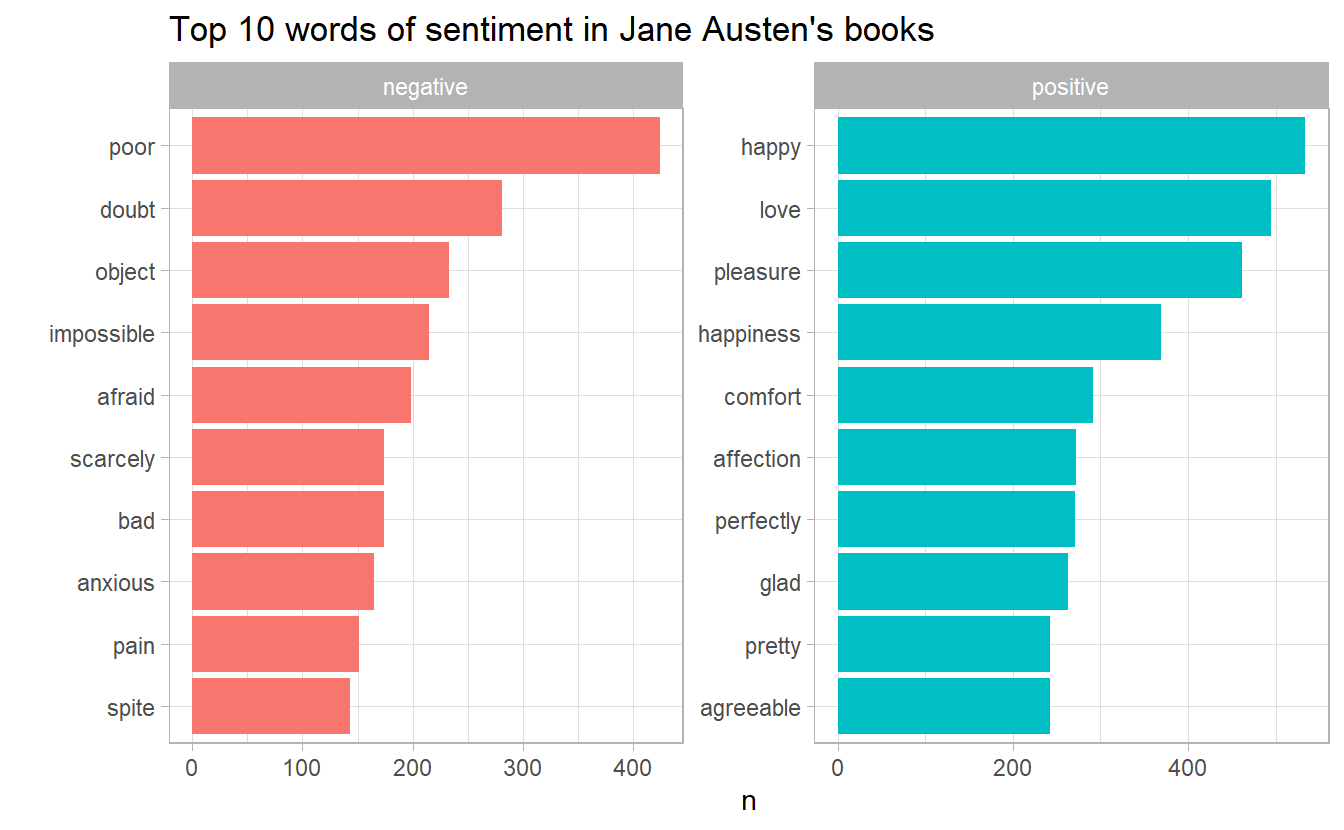
2.4 Most common positive and negative words
bing_word_counts <- tidy_books %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()
bing_word_counts
#> # A tibble: 2,585 x 3
#> word sentiment n
#> <chr> <chr> <int>
#> 1 miss negative 1855
#> 2 well positive 1523
#> 3 good positive 1380
#> 4 great positive 981
#> 5 like positive 725
#> 6 better positive 639
#> # ... with 2,579 more rowsThe word “miss” is coded as negative but it is used as a title for young, unmarried women in Jane Austen’s works. If it were appropriate for our purposes, we could easily add “miss” to a custom stop-words list using bind_rows(). We could implement that with a strategy such as this:
custom_stop_words <- tibble(word = c("miss"), lexicon = c("custom")) %>%
bind_rows(stop_words)
bing_word_counts <- tidy_books %>%
inner_join(get_sentiments("bing")) %>%
anti_join(custom_stop_words) %>%
group_by(sentiment) %>%
count(word, sentiment, sort = T) %>%
ungroup()Then we can make a bar plot
bing_word_counts %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup() %>%
facet_bar(y = word, x = n, by = sentiment, nrow = 1) +
labs(title = "Top 10 words of sentiment in Jane Austen's books")